LLVM IR入门指南
本仓库是我写的LLVM IR入门指南。
推荐前往https://Evian-Zhang.github.io/llvm-ir-tutorial阅读以获得最佳排版及语法高亮体验。PDF版本下载请点击前述网页的右上角。本教程中涉及的大部分代码也都在本GitHub仓库Evian-Zhang/llvm-ir-tutorial中。
LLVM是当下最通用的编译器后端之一,无论是想自己动手制作一个编译器,还是为主流的编程语言增加功能,又或者是做软件的静态分析,都离不开LLVM。LLVM IR是LLVM架构中一个重要的组成成分,编译器前端将抽象语法树转变为LLVM IR,而编译器后端则根据LLVM IR进行优化,生成可执行程序。但是,目前对LLVM IR的中文介绍少之又少。因此,我就写了这样的一系列文章,介绍了LLVM的架构,并且从LLVM IR的层面,让大家系统地了解LLVM。
最近(2023年6月),这个GitHub仓库的star数即将达到一千。因此,我打算基于现有的脉络,大范围更新现有的文章,推出LLVM IR入门指南2.0版(如需查看1.0版,请移步v1分支)。我这次更新的原因主要有以下几点:
-
LLVM版本更新
LLVM是一个不断演进的,由社区积极维护的项目。本系列文章写作于2020年,会有一些落后的知识点,也会有一些新的技术没有涵盖到。因此,本次更新将针对最新的LLVM 16进行写作。
-
操作系统变化
在1.0版中,我是以macOS为操作系统来介绍的。但是,随着Apple Silicon Mac占据主流地位,使用Intel芯片的Mac越来越少。由于文章中会大量地使用LLVM IR编译后的AMD64汇编指令作为解释说明,所以本次更新将从macOS转变为Linux,从而也可以使更多的读者能够在自己的机器中对文章中的代码进行验证。
-
知识水平提升
在过去的这三年里,我也学习了很多新的知识。并且,我也写出了不少关于底层二进制相关的系列文章,如:
-
针对Intel芯片Mac的macOS下AMD64架构汇编入门教程
-
针对Apple Silicon Mac的macOS下AArch64架构汇编入门教程
-
针对浏览器中的前端新宠儿WebAssembly汇编入门教程
在这些经验的积累下,我可以更具体、更准确地对文章的内容进行修补。
-
本人水平有限,写此系列文章仅希望与大家分享学习经验,文章中必有缺漏、错误之处,望方家不吝斧正,与大家共同学习,共同进步,谢谢大家!
前置知识
本系列文章所需的前置知识包括
- 掌握Linux基本命令(如使用命令行等)
- 掌握C语言编程知识
- 掌握AMD64指令集汇编知识
环境
本系列文章使用的环境包括
-
CPU
Intel i9-12900K
-
操作系统
Ubuntu 22.04,内核为Linux 5.19.0
-
编译器
C语言采用Clang 16编译器。LLVM采用LLVM 16版本。
本地生成可阅读版本
本系列文章可以在GitHub Pages https://Evian-Zhang.github.io/llvm-ir-tutorial上阅读并生成PDF。如果想在本地离线阅读,可以按照如下步骤生成可阅读版本。
1. 克隆本仓库
git clone https://github.com/Evian-Zhang/llvm-ir-tutorial && cd llvm-ir-tutorial
2. 准备语法高亮文件
由于MDBook自带的highlightjs并不支持本书的所有语法高亮,所以需要按照其官方文档中Custom theme的步骤准备自定义的语法高亮文件:
git clone https://github.com/highlightjs/highlight.js && cd highlight.js
npm install
node tools/build.js \
bash \
c \
llvm \
x86asm \
plaintext \
shell \
rust
cd ..
mkdir -p theme
cp highlight.js/build/highlight.min.js theme/highlight.js
3. 使用MDBook生成最终文档
使用MDBook,其可通过cargo install mdbook进行安装。
mdbook build
生成的文档将位于book/目录下。
同时,也可以使用
mdbook serve
在本地启动一个服务器,从而可以更方便地在浏览器中阅读。
License
本仓库遵循CC-BY-4.0版权协议。作为copyleft的支持者之一,我由衷地欢迎大家积极热情地参与到开源社区中。Happy coding!
LLVM架构简介
LLVM是什么
随着计算机技术的不断发展以及各种领域需求的增多,近几年来,许多编程语言如雨后春笋般出现,大多为了解决某一些特定领域的需求,比如说为JavaScript增加静态类型检查的TypeScript,为解决服务器端高并发的Golang,为解决内存安全和线程安全的Rust。
让我们设身处地地想象一下,如果我们想开发一门新的编译型的编程语言,有什么需要解决的问题呢?
-
怎样让我的编程语言能在尽可能多的平台上运行
我想让我的编程语言能够在Windows、macOS和Linux上都可以运行;我想让我的编程语言能够在Intel芯片、ARM芯片,乃至龙芯上都可以运行。
-
怎样让我的编程语言可以使用前人先进的技术
在编程语言发展的过程中,有许许多多成熟的技术。从汇编指令层面来看,简单地想给一个变量值置0,AMD64架构下可以用
xor %eax, %eax异或自身,AArch64架构下可以用mov w0, wzr使用零寄存器;从算法层面来看,可以使用尾调用优化、CFI等。如果我不想重复造轮子,该如何复用这些技术呢? -
怎样让我的编程语言在汇编层面实现「定制」
高级语言中的函数名,在汇编层面,我想让他换个名字;我想让C语言库能用它的调用约定来调用我的高级语言中的函数。
有的编程语言选择了使用C语言来解决这种问题,如早期的Haskell等。它们将使用自己语言的源代码编译成C代码,然后再在各个平台调用C编译器来生成可执行程序。为什么要选择C作为目标代码的语言呢?有几个原因:
- 绝大部分的操作系统都是由C和汇编语言写成,因此平台大多会提供一个C编译器可以使用,这样就解决了第一个问题
- 绝大部分的操作系统都会提供C语言的接口,以及C库。我们的编程语言因此可以很方便地调用相应的接口来实现更广泛的功能
- C语言本身并没有笨重的运行时,代码很贴近底层,可以使用一定程度的定制
以上三个理由让许多的编程语言开发者选择将自己的语言编译成C代码。
然而,我们知道,一个平台最终运行的二进制可执行文件,实际上就是在运行与之等价的汇编代码。与汇编代码比起来,C语言还是太抽象了,我们希望能更灵活地操作一些更底层的部分。同时,我们也希望相应代码在各个平台能有和C语言一致,甚至比其更好的优化程度。
因此,LLVM出现后,成了一个更好的选择。我们可以从LLVM官网中看到:
The LLVM Core libraries provide a modern source- and target-independent optimizer, along with code generation support for many popular CPUs (as well as some less common ones!) These libraries are built around a well specified code representation known as the LLVM intermediate representation (“LLVM IR”). The LLVM Core libraries are well documented, and it is particularly easy to invent your own language (or port an existing compiler) to use LLVM as an optimizer and code generator.
简单地说,LLVM代替了C语言在现代语言编译器实现中的地位。我们可以将自己语言的源代码编译成LLVM中间代码(LLVM IR),然后由LLVM自己的后端对这个中间代码进行优化,并且编译到相应的平台的二进制程序。
LLVM的优点正好对应我们之前讲的三个问题:
-
LLVM后端支持的平台很多,我们不需要担心CPU、操作系统的问题
有一点需要指出的是,操作系统API的调用还是得由编程语言开发者自己实现,LLVM不负责这个。例如,编程语言的标准库中,打开一个文件,其底层实现在Linux中是否是
open系统调用,在Windows中是否是CreateFile函数,这都得编程语言开发者自己实现。 -
LLVM后端的优化水平较高,我们只需要将代码编译成LLVM IR,就可以由LLVM后端作相应的优化
但我们需要知道一点,LLVM IR毕竟是更为底层的语言,在高级语言中的许多细节,都会在LLVM IR中丢失。因此,高级语言中能做的优化,还是得趁早做,把一大堆未经优化的LLVM IR丢给LLVM后端去优化,会严重拖慢编译时间,降低生成的二进制程序的性能。
-
LLVM IR本身比较贴近汇编语言,同时也提供了许多ABI层面的定制化功能
因为LLVM的优越性,除了LLVM自己研发的C编译器Clang,许多新的工程都选择了使用LLVM,我们可以在其官网看到使用LLVM的项目的列表,其中,最著名的就是Rust、Swift等语言了。
LLVM架构
要解释使用LLVM后端的编译器整体架构,我们就拿最著名的C语言编译器Clang为例。
在一台x86_64指令集的Linux系统上,我有一个最简单的C程序test.c:
int main() {
return 0;
}
我们使用
clang test.c -o test
究竟经历了哪几个步骤呢?
前端的语法分析
首先,Clang的前端编译器会将这个C语言的代码进行预处理、语法分析、语义分析,也就是我们常说的parse the source code。这里不同语言会有不同的做法。总之,我们是将「源代码」这一字符串转化为内存中有意义的数据,表示我们这个代码究竟想表达什么。
我们可以使用
clang -Xclang -ast-dump -fsyntax-only test.c
输出我们test.c经过编译器前端的预处理、语法分析、语义分析之后,生成的抽象语法树(AST):
TranslationUnitDecl 0x55aa2dae4c58 <<invalid sloc>> <invalid sloc>
|-TypedefDecl 0x55aa2dae5480 <<invalid sloc>> <invalid sloc> implicit __int128_t '__int128'
| `-BuiltinType 0x55aa2dae5220 '__int128'
|-TypedefDecl 0x55aa2dae54f0 <<invalid sloc>> <invalid sloc> implicit __uint128_t 'unsigned __int128'
| `-BuiltinType 0x55aa2dae5240 'unsigned __int128'
|-TypedefDecl 0x55aa2dae57f8 <<invalid sloc>> <invalid sloc> implicit __NSConstantString 'struct __NSConstantString_tag'
| `-RecordType 0x55aa2dae55d0 'struct __NSConstantString_tag'
| `-Record 0x55aa2dae5548 '__NSConstantString_tag'
|-TypedefDecl 0x55aa2dae5890 <<invalid sloc>> <invalid sloc> implicit __builtin_ms_va_list 'char *'
| `-PointerType 0x55aa2dae5850 'char *'
| `-BuiltinType 0x55aa2dae4d00 'char'
|-TypedefDecl 0x55aa2dae5b88 <<invalid sloc>> <invalid sloc> implicit __builtin_va_list 'struct __va_list_tag[1]'
| `-ConstantArrayType 0x55aa2dae5b30 'struct __va_list_tag[1]' 1
| `-RecordType 0x55aa2dae5970 'struct __va_list_tag'
| `-Record 0x55aa2dae58e8 '__va_list_tag'
`-FunctionDecl 0x55aa2db40e10 <test.c:1:1, line:3:1> line:1:5 main 'int ()'
`-CompoundStmt 0x55aa2db40f30 <col:12, line:3:1>
`-ReturnStmt 0x55aa2db40f20 <line:2:2, col:9>
`-IntegerLiteral 0x55aa2db40f00 <col:9> 'int' 0
这一长串输出看上去就让人眼花缭乱,然而,我们只需要关注最后四行:
`-FunctionDecl 0x55aa2db40e10 <test.c:1:1, line:3:1> line:1:5 main 'int ()'
`-CompoundStmt 0x55aa2db40f30 <col:12, line:3:1>
`-ReturnStmt 0x55aa2db40f20 <line:2:2, col:9>
`-IntegerLiteral 0x55aa2db40f00 <col:9> 'int' 0
这才是我们源代码的AST。可以很方便地看出,经过Clang前端的预处理、语法分析、语义分析,我们的代码被分析成一个函数,其函数体是一个复合语句,这个复合语句包含一个返回语句,返回语句中使用了一个整型字面量0。
因此,总结而言,我们基于LLVM的编译器的第一步,就是将源代码转化为内存中的抽象语法树AST。
前端生成中间代码
第二个步骤,就是根据内存中的抽象语法树AST生成LLVM IR中间代码(有的比较新的编译器还会先将AST转化为MLIR再转化为IR)。
我们知道,我们写编译器的最终目的,是将源代码交给LLVM后端处理,让LLVM后端帮我们优化,并编译到相应的平台。而LLVM后端为我们提供的中介,就是LLVM IR。我们只需要将内存中的AST转化为LLVM IR就可以放手不管了,接下来的所有事都是LLVM后端帮我们实现。
关于LLVM IR,我在下面会详细解释。我们现在先看看将AST转化之后,会产生什么样的LLVM IR。我们使用
clang -S -emit-llvm test.c
这时,会生成一个test.ll文件:
; ModuleID = 'test.c'
source_filename = "test.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
store i32 0, ptr %1, align 4
ret i32 0
}
attributes #0 = { noinline nounwind optnone uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1, !2, !3, !4}
!llvm.ident = !{!5}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 8, !"PIC Level", i32 2}
!2 = !{i32 7, !"PIE Level", i32 2}
!3 = !{i32 7, !"uwtable", i32 2}
!4 = !{i32 7, !"frame-pointer", i32 2}
!5 = !{!"Homebrew clang version 16.0.6"}
这看上去更加让人迷惑。然而,我们同样地只需要关注五行内容:
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
store i32 0, ptr %1, align 4
ret i32 0
}
这是我们AST转化为LLVM IR中最核心的部分,可以隐约感受到这个代码所表达的意思。
LLVM后端优化IR
LLVM后端在读取了IR之后,就会对这个IR进行优化。这在LLVM后端中是由opt这个组件完成的,它会根据我们输入的LLVM IR和相应的优化等级,进行相应的优化,并输出对应的LLVM IR。
我们可以用
opt test.ll -S --O3
对相应的代码进行优化,也可以直接用
clang -S -emit-llvm -O3 test.c
优化,并输出相应的优化结果:
; ModuleID = 'test.c'
source_filename = "test.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
; Function Attrs: mustprogress nofree norecurse nosync nounwind willreturn memory(none) uwtable
define dso_local i32 @main() local_unnamed_addr #0 {
ret i32 0
}
attributes #0 = { mustprogress nofree norecurse nosync nounwind willreturn memory(none) uwtable "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1, !2, !3}
!llvm.ident = !{!4}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 8, !"PIC Level", i32 2}
!2 = !{i32 7, !"PIE Level", i32 2}
!3 = !{i32 7, !"uwtable", i32 2}
!4 = !{!"Homebrew clang version 16.0.6"}
我们观察@main函数,可以发现其函数体从最开始的三行,变成了最终的一行。
值得注意的是,实际上,上述的这个优化只能通过clang -S -emit-llvm -O3 test.c生成;如果对我们之前生成的test.ll使用opt test.ll -S --O3,是不会有变化的。这是因为在Clang的D28404这个修改中,默认给所有O0优化级别的函数增加optnone属性,会导致函数不会被优化。如果要使opt test.ll -S --O3正确运行,我们生成test.ll时需要使用
clang -cc1 -disable-O0-optnone -S -emit-llvm test.c
来生成。
LLVM后端生成汇编代码
LLVM后端帮我们做的最后一步,就是由LLVM IR生成汇编代码,这是由llc这个组件完成的。
我们可以用
llc test.ll
生成test.s:
.text
.file "test.c"
.globl main # -- Begin function main
.p2align 4, 0x90
.type main,@function
main: # @main
.cfi_startproc
# %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movl $0, -4(%rbp)
xorl %eax, %eax
popq %rbp
.cfi_def_cfa %rsp, 8
retq
.Lfunc_end0:
.size main, .Lfunc_end0-main
.cfi_endproc
# -- End function
.ident "Homebrew clang version 16.0.6"
.section ".note.GNU-stack","",@progbits
这就回到了我们熟悉的汇编代码中。
有了汇编代码之后,我们就需要调用操作系统自带的汇编器、链接器,最终生成可执行程序。
LLVM IR
根据我们上面讲的,我们可以用以下步骤模拟一个基于LLVM后端的编译器的整体过程:
.c --frontend--> AST --frontend--> LLVM IR --LLVM opt--> LLVM IR --LLVM llc--> .s Assembly --OS Assembler--> .o --OS Linker--> executable
之所以说是「模拟」这一过程,是因为在真正的编译器中,必然是直接通过链接LLVM库的形式进行开发,上述的LLVM IR生成、优化、汇编代码生成,都是通过调用相应的函数来实现的,而非手动使用相应的程序来完成。
根据上述的步骤,我们可以发现,LLVM IR是连接编译器前端与LLVM后端的一个桥梁。同时,整个LLVM后端也是围绕着LLVM IR来进行的。所以,我的这个系列就是打算做成一个LLVM IR的入门级教程。
值得指出的一点是,在这一系列文章中,将不会介绍怎样通过LLVM的API来实现一个编译器(这个往往已经有了非常多的教程介绍),而是从LLVM IR的层面,让我们对LLVM有一个大致的认识,以方便我们之后真正实现编译器时,快速开发、调试相应的过程。
那么,LLVM IR究竟是什么呢?它的全称是LLVM Intermediate Representation,也就是LLVM的中间表示,我们可以在这篇LangRef中查看其所有信息。这看起来模糊不清的名字,也容易让人产生疑问。事实上,在我理解中,LLVM IR同时表示了三种东西:
- 内存中的LLVM IR
- 比特码形式的LLVM IR
- 可读形式的LLVM IR
内存中的LLVM IR是编译器作者最常接触的一个形式,也是其最本质的形式。当我们在内存中处理抽象语法树AST时,需要根据当前的项,生成对应的LLVM IR,这也就是编译器前端所做的事。我们的编译器前端可以用许多语言写,LLVM也为许多语言提供了Binding,但其本身还是用C++写的,所以这里就拿C++为例。
LLVM的C++接口在llvm/IR目录下提供了许多的头文件,如llvm/IR/Instructions.h等,我们可以使用其中的Value, Function, ReturnInst等等成千上万的类来完成我们的工作。也就是说,我们并不需要把AST变成一个个字符串,如ret i32 0等,而是需要将AST变成LLVM提供的IR类的实例,然后在内存中交给LLVM后端处理。
而比特码形式和可读形式则是将内存中的LLVM IR持久化的方法。比特码是采用特定格式的二进制序列,而可读形式的LLVM IR则是采用特定格式的human readable的代码。我们可以用
clang -S -emit-llvm test.c
生成可读形式的LLVM IR文件test.ll,采用
clang -c -emit-llvm test.c
生成比特码形式的LLVM IR文件test.bc,采用
llvm-as test.ll
将可读形式的test.ll转化为比特码test.bc,采用
llvm-dis test.bc
将比特码test.bc转化为可读形式的test.ll。
我这个系列,将主要介绍的是可读形式的LLVM IR的语法。
LLVM的下载与安装
我们可以直接在LLVM的官网上下载LLVM全部套件,但也可以去相应的系统包管理器中下载。对于国内用户而言,可以参考清华源的LLVM APT 软件仓库镜像使用帮助。
Hello world
在系统学习LLVM IR语法之前,我们应当首先掌握的是使用LLVM IR写的最简单的程序,也就是大家常说的Hello world版程序。这是因为,编程语言的学习,往往需要伴随着练习。但是一个独立的程序需要许多的前置语法基础,那么我们不可能在了解了所有前置语法基础之后才完成第一个独立程序。因此,正确的学习方式应该是,首先掌握这门语言独立程序的基础框架,然后每学习一个新的语法知识,就在框架中练习,并编译看结果是否是自己期望的结果。
综上所述,学习一门语言的第一步,就是掌握其最简单的程序的基本框架是如何写的。
最基本的程序
我们最基本的程序为:
; main.ll
define i32 @main() {
ret i32 0
}
这个程序可以看作最简单的C语言代码:
int main() {
return 0;
}
在Linux上编译而成的结果。
我们可以直接测试这个代码的正确性:
clang main.ll -o main
./main
使用clang可以直接将main.ll编译成可执行文件main。运行这个程序后,程序自动退出,并返回0。这正符合我们的预期。
基本概念
下面,我们对main.ll逐行解释一些比较基本的概念。
注释
首先,第一行; main.ll。这是一个注释。在LLVM IR中,注释以;开头,并一直延伸到行尾。所以在LLVM IR中,并没有像C语言中的/* comment block */这样的注释块,而全都类似于C语言中// comment line这样的注释行。
主程序
我们知道,主程序是可执行程序执行的入口点,所以任何可执行程序都需要main函数才能运行。所以,
define i32 @main() {
ret i32 0
}
就是这段代码的主程序。关于正式的函数、指令的定义,我会在之后的文章中提及。这里我们只需要知道,在@main()之后的,就是这个函数的函数体,ret i32 0就代表C语言中的return 0;。因此,如果我们要增加代码,就只需要在大括号内,ret i32 0前增加代码即可。
目标平台和数据布局
目标平台
在我们使用clang编译这个LLVM IR代码时,实际上会报一个警告:
warning: overriding the module target triple with x86_64-unknown-linux-gnu [-Woverride-module]
这里所说的「target triple」是什么呢?
要搞清楚这个概念,我们就需要回忆一下之前提到的,LLVM解决的一大问题:可移植性。也就是,我们想让我们的编程语言,在尽可能多的平台上得到支持。所谓的平台,直观来看,就是CPU和操作系统。
众所周知,不同指令集的CPU,它们能够运行的二进制指令必然不同,对应的汇编代码也完全不一样。而对于不同的操作系统来说,其支持的可执行程序格式是不同的。Linux支持ELF格式的可执行程序,macOS支持Mach-O格式的可执行程序,Windows支持PE格式的可执行程序。不同格式之间,其所包含的元信息不同,二进制指令的组织形式也有可能不同。
即使CPU和操作系统一致,也有可能会有一些其他的原因导致生成的二进制程序不一致。因此,我们往往还会加上「vendor」这一项。所以笼统而言,CPU–vendor–OS这三者决定了一个平台,只要这三者一致,我们生成的二进制程序往往就可以确定了。这三者就被称为一个「目标三元组」(Target Triple)。
对于我们的实验环境,也就是AMD64架构下的Linux,往往会被称为x86_64-unknown-linux-gnu,这里x86_64指的是CPU架构,unknown是vendor,对于Linux环境,往往不太重要;linux指的是操作系统,而后面跟着的gnu则是指Linux是GNU-Linux,主打一个修饰作用。
类似地,在Apple Silicon Mac上的目标三元组就是aarch64-apple-darwin,在常见的PC机上的目标三元组就是x86_64-pc-windows-msvc。
如果想消除编译时的警告,可以使用
clang main.ll -o main --mtriple "x86_64-unknown-linux-gnu"
或者在main.ll中加入一行
target triple = "x86_64-unknown-linux-gnu"
目标数据布局
除了目标平台外,我们还可以声明目标数据布局(Target Data Layout)。熟悉汇编语言以及二进制程序的开发者应该知道,我们在高级语言中常见的整型,如C中的int、short,Rust中的usize、i8,在底层看来,大小端序、数据长度、数据对齐是不得不考虑的事。我们在声明目标平台时,往往就默认了其对应的数据布局。例如,对于AMD64架构的Linux来说,数据往往使用小端序,8位长度的数据按8位对齐。
LLVM也支持我们手动定制这样的数据布局,例如,我们可以在LLVM IR的源代码中写:
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
这一长串文字就定义了目标的数据布局。具体而言:
e: 小端序m:e: 符号表中使用ELF格式的命名修饰p270:32:32-p271:32:32-p272:64:64: 与地址空间有关i64:64: 将i64类型的变量采用64位的ABI对齐f80:128: 将long double类型的变量采用128位的ABI对齐n8:16:32:64: 目标CPU的原生整型包含8位、16位、32位和64位S128: 栈以128位自然对齐
具体每个参数的含义,可以参考Data Layout。
数据表示
LLVM IR和其它的汇编语言类似,其核心就是对数据的操作。这涉及到了两个问题:什么数据和怎么操作。具体到这篇文章中,我就将介绍的是,在LLVM IR中,是如何表示一个数据的。
汇编层次的数据表示
LLVM IR是最接近汇编语言的一层抽象,所以我们首先需要了解在计算机底层,汇编语言的层次中,数据是怎样表示的。
谈到汇编层次的数据表示,一个老生常谈的程序就是
#include <stdlib.h>
int global_data = 0;
int main() {
int stack_data = 0;
int *heap_pointer = (int *)malloc(16 * sizeof(int));
return 0;
}
我们知道,一个C语言从代码到执行的过程是代码–>硬盘上的二进制程序–>内存中的进程。在代码被编译到二进制程序的时候,global_data本身就写在了二进制程序中。在操作系统将二进制程序载入内存时,就会在特定的区域(数据区)初始化这些值。而stack_data代表的局部变量,则是在程序执行其所在的函数时,在栈上初始化,类似地,heap_pointer这个指针也是在栈上,而其指向的内容,则是操作系统分配在堆上的。
用一个图可以简单地表示:
+------------------------------+
| stack_data |
| heap_pointer | <------------- stack
+------------------------------+
| |
| | <------------- available memory space
| |
+------------------------------+
| data pointed by heap_pointer | <------------- heap
+------------------------------|
| global_data | <------------- .data section
+------------------------------+
这就是一个简化后的进程的内存模型。也就是说,一共有三种数据:
- 栈上的数据
- 堆中的数据
- 数据区里的数据
但是,我们仔细考虑一下,在堆中的数据,能否独立存在。操作系统提供的在堆上创建数据的接口如malloc等,都是返回一个指针,那么这个指针会存在哪里呢?寄存器里,栈上,数据区里,或者是另一个被分配在堆上的指针。也就是说,可能会是:
#include <stdlib.h>
int *global_pointer = (int *)malloc(16 * sizeof(int));
int main() {
int *stack_pointer = (int *)malloc(16 * sizeof(int));
int **heap_pointer = (int **)malloc(sizeof(int *));
*heap_pointer = (int *)malloc(16 * sizeof(int));
return 0;
}
但不管怎样,堆中的数据都不可能独立存在,一定会有一个位于其他位置的引用。所以,在内存中的数据按其表示来说,一共分为两类:
- 栈上的数据
- 数据区里的数据
除了内存之外,还有一个存储数据的地方,那就是寄存器。因此,我们在程序中可以用来表示的数据,一共分为三类:
- 寄存器中的数据
- 栈上的数据
- 数据区里的数据
数据区与符号表
我们知道,数据区里的数据,其最大的特点就是,能够给整个程序的任何一个地方使用。同时,数据区里的数据也是占静态的二进制可执行程序的体积的。所以,我们应该只将需要全程序使用的变量放在数据区中。而现代编程语言的经验告诉我们,这类全局静态变量应该越少越好。
同时,由于LLVM是面向多平台的,所以我们还需要考虑的是该怎么处理这些数据。一般来说,大多数平台的可执行程序格式中都会包含.data分区,用来存储这类的数据。但除此之外,每个平台还有专门的更加细致的分区,比如说,Linux的ELF格式中就有.rodata来存储只读的数据。因此,LLVM的策略是,让我们尽可能细致地定义一个全局变量,比如说注明其是否只读等,然后依据各个平台,如果平台的可执行程序格式支持相应的特性,就可以进行优化。
一般来说,在LLVM IR中定义一个存储在数据区中的全局变量,其格式为:
@global_variable = global i32 0
这个语句定义了一个i32类型的全局变量@global_variable,并且将其初始化为0。
如果是只读的全局变量,也就是常量,我们可以用constant来代替global:
@global_constant = constant i32 0
这个语句定义了一个i32类型的全局常量@global_constant,并将其初始化为0。
符号与符号表
讲到了数据区,就顺便讲讲符号表。在LLVM IR中,所有的全局变量的名称都需要用@开头。我们有一个这样的LLVM IR:
; global_variable_test.ll
@global_variable = global i32 0
define i32 @main() {
ret i32 0
}
也就是说,在之前最基本的程序的基础上,新增了一个全局变量@global_variable。我们将其直接编译成可执行文件:
clang global_variable_test.ll -o global_variable_test
然后,我们使用nm命令查看其符号表:
nm global_variable_test
我们可以在输出中找到一行:
000000000000402c B global_variable
我们注意到,出现了global_variable这个字段。这表明,直接定义的全局变量,其名称会出现在符号表之中。那么,怎么控制这个行为呢?首先,我们需要简单地了解一下符号与符号表。
在传统的C语言编译模型中,编译器将每个.c文件(也称为「编译单元」)编译为一个.o目标文件,然后链接器将这些.o文件链接为一个可执行文件。这么做的好处是,如果一个项目特别大,编译器就不需要将所有.c文件都读入内存中一起处理,而是可以并行地、高效地单独处理每个.c文件(这也是著名前端框架React不选择使用TypeScript的原因之一,参见为什么 React 源码不用 TypeScript 来写? - Cat Chen的回答 - 知乎)。对于动态链接的程序而言,在程序加载、运行时,也会由动态链接器将相应的库动态链接进程序之中。
也就是说,编译器生成的结果,需要给链接器和动态链接器进行处理。在这一过程中,就需要「符号表」出马了。在上述的过程中,编译器的输入是一个编译单元,而输出是一个目标文件。那么如果我们在源代码中,在一个.c文件中调用了别的文件中实现的函数,编译器并不知道别的函数在哪。因此,编译器选择的策略是将这个函数的调用用一个符号代替,在将来链接以及动态链接的时候,再进行替换。
粗略来讲,整体的符号处理的过程为:
- 编译器对源代码按文件进行编译。对于每个文件中的未知函数,记录其符号;对于这个文件中实现的函数,暴露其符号
- 链接器收集所有的目标文件,对于每个文件而言,将其记录下的未知函数的符号,与其他文件中暴露出的符号相对比,如果找到匹配的,就成功地解析(resolve)了符号
- 部分符号在程序加载、执行时,由动态链接库给出。动态链接器将在这些阶段,进行类似的符号解析
这一流程粗粒度地来看,非常的简单。但是仔细来看,就需要更多的处理。
一个符号本身,就是一个字符串。那么我们在写一个C语言的项目时,如果希望有的函数在别的文件中被调用,按照上述过程,似乎就是暴露一下符号就行。但是,一个C语言的项目,往往会链接很多第三方库。如果我们想暴露的函数名与其他第三方库里的函数名重复了,会怎样呢?如果不加处理,链接器会直接报错。那难道我们起一个名字,需要注意与别的所有的库里的函数都不重复吗?此外,一个程序会有成千上万个符号,一些简单的,只在一个文件里用到的符号,比如说cmp、max,难道也要放在符号表中吗?
在LLVM IR中,解决这些问题,与两个概念密切相关:链接与可见性,LLVM IR也提供了Linkage Type和Visibility Styles这两个修饰符来控制相应的行为。
链接类型
对于链接类型,我们常用的主要有什么都不加(默认为external)、private和internal。
什么都不加的话,就像我们刚刚那样,直接把全局变量的名字放在了符号表中。这样的话,这个函数可以在链接时被其他编译单元看到。
用private,则代表这个变量的名字不会出现在符号表中。我们将原来的代码改写成
@global_variable = private global i32 0
那么,用nm查看其编译出的可执行文件,这个变量的名字就消失了。
用internal则表示这个变量是以局部符号的身份出现(全局变量的局部符号,可以理解成C中的static关键词)。我们将原来的代码改写成
@global_variable = internal global i32 0
那么,再次将其编译成可执行程序,并用nm查看,可以看到这个符号。但是,在链接过程中,这个符号并不会参与符号解析。
可见性
可见性在实际使用中则比较少,主要分为三种default, hidden和protected,这里主要的区别在于符号能否被重载。default的符号可以被重载,而protected的符号则不可以;此外,hidden则不将变量放在动态符号表中,因此其它的模块不可以直接引用这个符号。
可抢占性
在我们日常看到的LLVM IR中,会经常见到dso_local这样的修饰符,在LLVM中被称作运行时抢占性修饰符。如果需要深入理解这个概念,可以参考国人大神写的ELF interposition and -Bsymbolic、-fno-semantic-interposition。简单来说,dso_local保证了程序像我们想象中的一样运行。
举个例子:
// interposition1.c
void f(void) {
printf("From interposition1\n");
}
// interposition2.c
void f(void) {
printf("From interposition2\n");
}
void g(void) {
f();
}
// interposition-main.c
void g();
int main() {
g();
return 0;
}
我们想把interposition1.c和interposition2.c分别编译为动态链接库,并给main来调用。最简单的做法是:
clang -fPIC interposition1.c --shared -o libinterposition1.so
clang -fPIC interposition2.c --shared -o libinterposition2.so
clang -L. -linterposition1 -linterposition2 interposition-main.c -o interposition
我们运行这个程序,常理告诉我们,正常来说,得是输出“From interposition2“吧?但是,我们真正运行这个程序,会输出“From interposition1“。
我们如果看interposition2的汇编代码,会发现,g函数的实现为
g:
pushq %rbp
movq %rsp, %rbp
callq f@PLT
popq %rbp
retq
虽然f在同一个文件内,但它居然默认是去PLT表找实现!!
这不仅极其愚蠢(可能仅仅对通过LD_PRELOAD来hook API有帮助),而且效率还低。
但如果我们这样子来编译:
clang -fPIC interposition1.c --shared -o libinterposition1.so
clang -fPIC -fno-semantic-interposition interposition2.c --shared -o libinterposition2.so
clang -L. -linterposition1 -linterposition2 interposition-main.c -o interposition
仅仅在编译libinterposition2.so时增加了-fno-semantic-interposition这个选项,再运行程序,输出就对了!
如果我们查看生成的interposition2.ll,可以发现:
define dso_local void @f() {
%1 = call i32 (ptr, ...) @printf(ptr noundef @.str)
ret void
}
define dso_local void @g() {
call void @f()
ret void
}
f和g都有了dso_local的修饰符。dso_local就是告诉链接器,这个不许抢占,在生成动态链接库的时候,直接调用,别去PLT表找了。
当我们使用clang -O3等级别进行优化编译时,不需要加-fno-semantic-interposition就可以达成一样的效果。
根据Fedora社区的尝试Changes/PythonNoSemanticInterpositionSpeedup和cpython对应的issue Compile libpython with -fno-semantic-interposition,仅仅是增加这个选项,就可以让cpython快1.3倍。
C的例子
关于符号和符号表,这些还是挺抽象的,我们不如用一个具体的C语言的例子来看看效果:
int a;
extern int b;
static int c;
void d(void);
void e(void) {}
static void f(void) {}
首先我们先理解一下这个C语言代码各个符号的含义:
-
a定义在当前文件中的全局变量,别的文件也可以使用这个符号
-
b定义在别的文件中的全局变量,当前文件需要使用这个符号
-
c定义在当前文件中的全局变量,别的文件不可以使用这个符号
-
d定义在别的文件中的函数,当前文件需要使用这个符号
-
e定义在当前文件中的函数,别的文件也可以使用这个符号
-
f定义在当前文件中的函数,别的文件不可以使用这个符号
以上六种,是我们在C语言编程中最常见的符号形式。
我们使用Clang将其编译为LLVM IR,是什么样子的呢?
@a = dso_local global i32 0, align 4
@b = external global i32, align 4
@c = internal global i32 0, align 4
declare void @d()
define dso_local void @e() {
ret void
}
define internal void @f() {
ret void
}
我们可以发现几件事(在默认的编译选项下):
- C语言中的
static,也就是当前文件中定义,别的文件不可以用的,都会加上internal修饰符 - C语言中的
extern,也就是别的文件中定义的,全局变量会加上external修饰符,函数会使用declare - C语言中定义的,可以给别的文件使用的全局变量或函数,不会加上链接类型修饰符,并且会加上
dso_local保证不会被抢占
寄存器和栈
这两种数据我选择放在一起讲。我们知道,大多数对数据的操作,如加减乘除、比大小等,都需要操作的是寄存器内的数据。那么,我们为什么需要把数据放在栈上呢?主要有两个原因:
- 寄存器数量不够
- 需要操作内存地址
如果我们一个函数内有三四十个局部变量,但是家用型CPU最多也就十几个通用寄存器,所以我们不可能把所有变量都放在寄存器中。因此我们需要把一部分数据放在内存中,栈就是一个很好的存储数据的地方;此外,有时候我们需要直接操作内存地址,但是寄存器并没有通用的地址表示,所以只能把数据放在栈上来完成对地址的操作。
因此,在不操作内存地址的前提下,栈只是寄存器的一个替代品。有一个很简单的例子可以解释这个概念。我们有一个很简单的C程序:
// max.c
int max(int a, int b) {
if (a > b) {
return a;
} else {
return b;
}
}
int main() {
int a = max(1, 2);
return 0;
}
我们将其编译成汇编文件。我们首先来看max(1, 2)是如何调用的:
movl $1, %edi
movl $2, %esi
callq max
将参数1和2分别放到了寄存器edi和esi里。那么,max函数又是如何操作的呢?
pushq %rbp
movq %rsp, %rbp
movl %edi, -8(%rbp) # Move data stored in %edi to stack at -8(%rbp)
movl %esi, -12(%rbp) # Move data stored in %esi to stack at -12(%rbp)
movl -8(%rbp), %eax # Move data stored in stack at -8(%rbp) to register %eax
cmpl -12(%rbp), %eax # Compare data stored in stack at -12(%rbp) with data stored in %eax
jle .LBB0_2 # If compare result is less than or equal to, then go to label LBB0_2
movl -8(%rbp), %eax # Move data stored in stack at -8(%rbp) to register %eax
movl %eax, -4(%rbp) # Move data stored in %eax to stack at -4(%rbp)
jmp .LBB0_3 # Go to label LBB0_3
.LBB0_2:
movl -12(%rbp), %eax # Move data stored in stack at -12(%rbp) to register %eax
movl %eax, -4(%rbp) # Move data stored in %eax to stack at -4(%rbp)
.LBB0_3:
movl -4(%rbp), %eax # Move data stored in stack at -4(%rbp) to register %eax
popq %rbp
retq
考虑到篇幅,我将这个汇编每一个重要步骤所做的事都以注释形式写在了代码里面。这个看上去很复杂,但实际上做的是这样的事:
- 把
int a和int b看作局部变量,分别存储在栈上的-8(%rbp)和-12(%rbp)上 - 为了比较这两个局部变量,将一个由栈上导入寄存器
eax中 - 比较
eax寄存器中的值和另一个局部变量 - 将两者中比较大的那个局部变量存储在栈上的
-4(%rbp)上(由于x86_64架构不允许直接将内存中的一个值拷贝到另一个内存区域中,所以得先把内存区域中的值拷贝到eax寄存器里,再从eax寄存器里拷贝到目标内存中) - 将栈上
-4(%rbp)这个用来存储返回值的区域的值拷贝到eax中,并返回
这看上去真是太费事了。但是,这也是无可奈何之举。这是因为,在不开优化的情况下,一个C的函数中的局部变量(包括传入参数)和返回值都应该存储在函数本身的栈帧中,所以,我们得把这简单的两个值在不同的内存区域和寄存器里来回拷贝。
那么,如果我们优化一下会怎样呢?我们使用
clang -O1 -S max.c
之后,我们的max函数的汇编代码是:
movl %esi, %eax
cmpl %esi, %edi
cmovgl %edi, %eax
retq
那么长的一串代码竟然变的如此简洁了。这个代码翻译成伪代码就是
function max(register a, register b) {
register c = register b
if (register a >= register c) {
register c = register a
}
return register c
}
很简单的事,并且把所有的操作都从对内存的操作变成了对寄存器的操作。
因此,由这个简单的例子我们可以看出来,如果寄存器的数量足够,并且代码中没有需要操作内存地址的时候,寄存器是足够胜任的,并且更加高效的。
寄存器
正因为如此,LLVM IR引入了虚拟寄存器的概念。在LLVM IR中,一个函数的局部变量可以是寄存器或者栈上的变量。对于寄存器而言,我们只需要像普通的赋值语句一样操作,但需要注意名字必须以%开头:
%local_variable = add i32 1, 2
此时,%local_variable这个变量就代表一个寄存器,它此时的值就是1和2相加的结果。我们可以写一个简单的程序验证这一点:
; register_test.ll
define i32 @main() {
%local_variable = add i32 1, 2
ret i32 %local_variable
}
我们查看其编译出的汇编代码,其主函数为:
main:
movl $2, %eax
addl $1, %eax
retq
确实这个局部变量%local_variable变成了寄存器eax。
关于寄存器,我们还需了解一点。在不同的ABI下,会有一些callee-saved register和caller-saved register。简单来说,就是在函数内部,某些寄存器的值不能改变。或者说,在函数返回时,某些寄存器的值要和进入函数前相同。比如,在System V的ABI下,rbp, rbx, r12, r13, r14, r15都需要满足这一条件,这在System V的ABI下被称作callee-saved registe。由于LLVM IR是面向多平台的,所以我们需要一份代码适用于多种ABI。因此,LLVM IR内部自动帮我们做了这些事。如果我们把所有没有被保留的寄存器都用光了,那么LLVM IR会帮我们把这些被保留的寄存器放在栈上,然后继续使用这些被保留寄存器。当函数退出时,会帮我们自动从栈上获取到相应的值放回寄存器内。
那么,如果所有通用寄存器都用光了,该怎么办?LLVM IR会帮我们把剩余的值放在栈上,但是对我们用户而言,实际上都是虚拟寄存器,用户是感觉不到差别的。
因此,我们可以粗略地理解LLVM IR对寄存器的使用:
- 当所需寄存器数量较少时,直接使用caller-saved register,即不需要保留的寄存器
- 当caller-saved register不够时,将callee-saved register原本的值压栈,然后使用callee-saved register
- 当寄存器用光以后,就把多的虚拟寄存器的值压栈
因此,我们还可以注意到,如果在调用别的函数的过程中,如果调用方的非callee-saved register中存有一些后续需要用到的数据,需要将这些数据放入栈上,在函数调用结束后,再从栈上将这些值放回相应的寄存器中。
我们可以写一个简单的程序验证。对于x86_64架构下,我们只需要使用15个虚拟寄存器就可以验证这件事。鉴于篇幅,我就不把代码放在文章中了,如果想看详细代码可以去我的GitHub仓库中查看many_registers_test.ll。我们将其编译成汇编语言之后,可以看到在函数开头就有
pushq %r15
pushq %r14
pushq %r13
pushq %r12
pushq %rbx
也就是把那些需要保留的寄存器压栈。然后随着寄存器用光,第15个虚拟寄存器就会使用栈:
movl $2, %eax
addl $1, %eax
movl %eax, -4(%rsp)
栈
我们之前说过,当不需要操作地址并且寄存器数量足够时,我们可以直接使用寄存器。而LLVM IR的策略保证了我们可以使用无数的虚拟寄存器。那么,在需要操作地址以及需要可变变量(之后会提到为什么)时,我们就需要使用栈。
LLVM IR对栈的使用十分简单,直接使用alloca指令即可。如:
%local_variable = alloca i32
就可以声明一个在栈上的变量了。关于栈上变量的操作,我会在之后提到,目前我们对栈上变量的了解只需这么多。
数据的使用
在之前的两篇文章中,我们解释了LLVM中是如何对应数据区、寄存器和栈上的数据的。那么,这些数据定义了以后,该如何使用呢?
全局变量和栈上变量皆指针
下面,我们就需要讲怎样使用全局变量和栈上的变量。这两种变量实际上是类似的,LLVM IR把它们都看作指针。也就是说,对于全局变量:
@global_variable = global i32 0
和栈上变量
%local_variable = alloca i32
这两个变量实际上都是ptr指针,指向它们所处的一个i32大小的内存区域。所以,我们不能这样:
%1 = add i32 1, @global_variable ; Wrong!
因为@global_variable只是一个指针。
如果要操作这些值,必须使用load和store这两个命令。如果我们要获取@global_variable的值,就需要
%1 = load i32, ptr @global_variable
这个指令的意思是,把一个ptr指针@global_variable的i32类型的值赋给虚拟寄存器%1,然后我们就能愉快地
%2 = add i32 1, %1
这样了。
类似地,如果我们要将值存储到全局变量或栈上变量里,会需要store命令:
store i32 1, ptr @global_variable
这个代表将i32类型的值1赋给ptr类型的全局变量@global_variable所指的内存区域中。
SSA
LLVM IR是一个严格遵守SSA(Static Single Assignment)策略的语言。SSA的要求很简单:每个变量只被赋值一次。也就是说,你不能
%1 = add i32 1, 2
%1 = add i32 3, 4
对%1同时赋值两次是不被允许的。
SSA作为一个历史悠久的概念,已经有了相当成熟的相关技术。通过使用SSA,编译器可以进行更好的优化,应用更成熟的算法,得到更好的结果。这里因为个人能力有限,就不再多对SSA进行介绍。我们只需要知道,通过约束每个变量只被赋值一次,可以让LLVM更好地优化。
上面这个例子好做,直接把3加4的结果赋值给一个新的虚拟寄存器就好了。但是,并非所有的情况都这么简单。在一些复杂情况下,将值存储在栈上再取出来,或者使用phi指令(见之后控制语句一章),也是一个更好的选择。
类型系统
我们知道,汇编语言是弱类型的,我们操作汇编语言的时候,实际上考虑的是一些二进制序列。但是,LLVM IR却是强类型的,在LLVM IR中所有变量都必须有类型。这是因为,我们在使用高级语言编程的时候,往往都会使用强类型的语言,弱类型的语言无必要性,也不利于维护。因此,使用强类型语言,LLVM IR可以更好地进行优化。
基本的数据类型
LLVM IR中比较基本的数据类型包括:
- 空类型(
void) - 整型(
iN) - 浮点型(
float、double等)
空类型一般是作为不返回值的函数的返回类型,没有特别的含义,就代表「什么都没有」。
整型是指i1, i8, i16, i32, i64这类的数据类型。这里iN的N可以是任意正整数,可以是i3,i1942652。但最常用,最符合常理的就是i1以及8的整数倍。i1有两个值:true和false。也就是说,下面的代码可以正确编译:
%boolean_variable = alloca i1
store i1 true, ptr %boolean_variable
对于大于1位的整型,也就是如i8, i16等类型,我们可以直接用数字字面量赋值:
%integer_variable = alloca i32
store i32 128, ptr %integer_variable
store i32 -128, ptr %integer_variable
符号
有一点需要注意的是,在LLVM IR中,整型默认是有符号整型,也就是说我们可以直接将-128以补码形式赋值给i32类型的变量。在LLVM IR中,整型的有无符号是体现在操作指令而非类型上的,比方说,对于两个整型变量的除法,LLVM IR分别提供了udiv和sdiv指令分别适用于无符号整型除法和有符号整型除法:
%1 = udiv i8 -6, 2 ; Get (256 - 6) / 2 = 125
%2 = sdiv i8 -6, 2 ; Get (-6) / 2 = -3
我们可以用这样一个简单的程序验证:
; div_test.ll
define i8 @main() {
%1 = udiv i8 -6, 2
%2 = sdiv i8 -6, 2
ret i8 %1
}
分别将ret语句的参数换成%1和%2以后,将代码编译成可执行文件,在终端下运行并查看返回值即可。
总结一下就是,LLVM IR中的整型默认按有符号补码存储,但一个变量究竟是否要被看作有无符号数需要看其参与的指令。
转换指令
与整型密切相关的就是转换指令,比如说,将i8类型的数-127转换成i32类型的数,将i32类型的数257转换成i8类型的数等。总的来说,LLVM IR中提供三种指令:trunc .. to指令,zext .. to指令和sext .. to指令。
将长的整型转换成短的整型很简单,直接把多余的高位去掉就行,LLVM IR提供的是trunc .. to指令:
%trunc_integer = trunc i32 257 to i8 ; Trunc 32 bit 100000001 to 8 bit, get 1
将短的整型变成长的整型则相对比较复杂。这是因为,在补码中最高位是符号位,并不表示实际的数值。因此,如果单纯地在更高位补0,那么i8类型的-1(补码为11111111)就会变成i32的255。这虽然符合道理,但有时候我们需要i8类型的-1扩展到i32时仍然是-1。LLVM IR为我们提供了两种指令:零扩展的zext .. to指令和符号扩展的sext .. to指令。
零扩展就是最简单的,直接在高位补0,而符号扩展则是用原数的符号位来填充。也就是说我们如下的代码:
%zext_integer = zext i8 -1 to i32 ; Extend 8 bit 0xFF to 32 bit 0x000000FF, get 255
%sext_integer = sext i8 -1 to i32 ; Extend 8 bit 0xFF to 32 bit 0xFFFFFFFF, get -1
类似地,浮点型的数和整型的数也可以相互转换,使用fptoui .. to, fptosi .. to, uitofp .. to, sitofp .. to可以分别将浮点数转换为无符号、有符号整型,将无符号、有符号整型转换为浮点数。不过有一点要注意的是,如果将大数转换为小的数,那么并不保证截断,如将浮点型的257.1转换成i8(上限为128),那么就会产生未定义行为。所以,在浮点型和整型相互转换的时候,需要在高级语言层面做一些调整,如使用饱和转换等,具体方案可以看Rust最近1.45.0的更新Announcing Rust 1.45.0和GitHub上的PR:Out of range float to int conversions using as has been defined as a saturating conversion.。
指针类型
LLVM IR中的指针类型就是ptr。与C语言不同,LLVM IR中的指针不含有其指向内容的类型,也就是说,类似于C语言中的void *。我们之前提到,LLVM IR中的全局变量和栈上分配的变量都是指针,所以其类型都是指针类型。
在高级语言中,直接操作裸指针的机会都比较少,除非在性能极其敏感的场景下,由最厉害的大佬才能操作裸指针。这是因为,裸指针极其危险,稍有不慎就会出现段错误等致命错误,所以我们使用指针时应该慎之又慎。
LLVM IR为大佬们提供了操作裸指针的一些指令。在C语言中,我们会遇到这种场景:
int x, y;
size_t address_of_x = (size_t)&x;
size_t address_of_y = address_of_x - sizeof(int);
int also_y = *(int *)address_of_y;
这种场景比较无脑,但确实是合理的,需要将指针看作一个具体的数值进行加减。到x86_64的汇编语言层次,取地址就变成了lea命令,解引用倒是比较正常,就是一个简单的mov。
在LLVM IR层次,为了使指针能像整型一样加减,提供了ptrtoint .. to指令和inttoptr .. to指令,分别解决将指针转换为整型,和将整型转换为指针的功能。也就是说,我们可以粗略地将上面的程序转写为
%x = alloca i32 ; %x is of type ptr, which is the address of variable x
%y = alloca i32 ; %y is of type ptr, which is the address of variable y
%address_of_x = ptrtoint ptr %x to i64
%address_of_y = sub i64 %address_of_x, 4
%also_y = inttoptr i64 %address_of_y to ptr ; %also_y is of type ptr, which is the address of variable y
聚合类型
比起指针类型而言,更重要的是聚合类型。我们在C语言中常见的聚合类型有数组和结构体,LLVM IR也为我们提供了相应的支持。
数组类型很简单,我们要声明一个类似C语言中的int a[4],只需要
%a = alloca [4 x i32]
也就是说,C语言中的int[4]类型在LLVM IR中可以写成[4 x i32]。注意,这里面是个x不是*。
我们也可以使用类似地语法进行初始化:
@global_array = global [4 x i32] [i32 0, i32 1, i32 2, i32 3]
特别地,我们知道,字符串在底层可以看作字符组成的数组,所以LLVM IR为我们提供了语法糖:
@global_string = global [12 x i8] c"Hello world\00"
在字符串中,转义字符必须以\xy的形式出现,其中xy是这个转义字符的ASCII码。比如说,字符串的结尾,C语言中的\0,在LLVM IR中就表现为\00。
结构体的类型也相对比较简单,在C语言中的结构体
struct MyStruct {
int x;
char y;
};
在LLVM IR中就成了
%MyStruct = type {
i32,
i8
}
我们初始化一个结构体也很简单:
@global_structure = global %MyStruct { i32 1, i8 0 }
; or
@global_structure = global { i32, i8 } { i32 1, i8 0 }
值得注意的是,无论是数组还是结构体,其作为全局变量或栈上变量,依然是指针,也就是说,@global_array的类型是ptr, @global_structure的类型也是ptr。接下来的问题就是,我们如何对聚合类型进行操作呢?
在LLVM IR中,如果我们想对一个聚合类型的某些字段进行操作,需要区分这个聚合类型是指针形式的,也就是以全局变量或者栈形式存储,还是值形式的,也就是以寄存器形式存储。
getelementptr
首先,我们将介绍以指针形式存储的聚合类型,该如何访问其字段。
访问数组元素字段
我们先来看一个最直观的例子:
struct MyStruct {
int x;
int y;
};
void foo(struct MyStruct *my_structs_ptr) {
int my_y = my_structs_ptr[2].y;
}
我们有一个foo函数,其接收了一个参数my_structs_ptr。从函数体的语义可知,这里这个参数,实际上指向了一个数组,我们要取这个数组的第三个元素的y字段。
我们先直接看结论,用LLVM IR来表示为
%MyStruct = type { i32, i32 }
define void @foo(ptr %my_structs_ptr) {
%my_y_in_stack = alloca i32
%my_y_ptr = getelementptr %MyStruct, ptr %my_structs_ptr, i64 2, i32 1
%my_y_val = load i32, ptr %my_y_ptr
store i32 %my_y_val, ptr %my_y_in_stack
ret void
}
我们可以注意到,最核心的就是getelementptr指令了。它的四个参数的语义分别为
-
%MyStruct我们要取地址的指针,它指向区域的类型为
%MyStruct -
ptr %my_structs_ptr我们要操作的指针,是
ptr %my_structs_ptr -
i64 2取偏移量为2的那个元素,也就是
my_structs_ptr[2] -
i32 1对于获得到的那个元素,取索引为1的字段,也就是
my_structs_ptr[2].y
通过这个指令,我们获得了my_structs_ptr[2].y的地址,随后的LLVM IR指令就是将这个地址的值放到了局部变量中。
访问指针字段
接下来,我们看这样一个例子:
struct MyStruct {
int x;
int y;
};
void foo(struct MyStruct *my_structs_ptr) {
int my_y = my_structs_ptr->y;
}
其对应的LLVM IR为
%MyStruct = type { i32, i32 }
define void @foo(ptr %my_structs_ptr) {
%my_y_in_stack = alloca i32
%my_y_ptr = getelementptr %MyStruct, ptr %my_structs_ptr, i64 0, i32 1
%my_y_val = load i32, ptr %my_y_ptr
store i32 %my_y_val, ptr %my_y_in_stack
ret void
}
唯一的改动,就是将之前的偏移量i64 2改为i64 0。
这看上去挺符合直觉的。等等,符合直觉吗?
我们发现,即使是将my_structs_ptr看作是指向结构体的指针,而非指向数组的指针,仍然要加一个偏移量0。这是因为,C语言中,对于一个数组array,&array[0]和指向首元素的array_ptr是同一个东西。为了兼容C语言这个特性,LLVM IR在getelementptr中,将所有的指针都看作一个指向数组首地址的指针。因此,我们需要额外加一个i64 0的偏移量来解决这个问题。
级联访问
此外,getelementptr还可以接多个参数,类似于级联调用。我们有C程序:
struct MyStruct {
int x;
int y[5];
};
struct MyStruct my_structs[4];
那么如果我们想获得my_structs[2].y[3]的地址,只需要
%MyStruct = type {
i32,
[5 x i32]
}
%my_structs = alloca [4 x %MyStruct]
%1 = getelementptr %MyStruct, ptr %my_structs, i64 2, i32 1, i64 3
我们可以查看官方提供的The Often Misunderstood GEP Instruction指南更多地了解getelementptr的机理。
extractvalue和insertvalue
除了我们上面讲的这种情况,也就是把结构体分配在栈或者全局变量,然后操作其指针以外,还有什么情况呢?我们考虑这种情况:
; extract_insert_value.ll
%MyStruct = type {
i32,
i32
}
@my_struct = global %MyStruct { i32 1, i32 2 }
define i32 @main() {
%1 = load %MyStruct, ptr @my_struct
ret i32 0
}
这时,我们的结构体是直接放在虚拟寄存器%1里,%1并不是存储@my_struct的指针,而是直接存储这个结构体的值。这时,我们并不能用getelementptr来操作%1,因为这个指令需要的是一个指针。因此,LLVM IR提供了extractvalue和insertvalue指令。
因此,如果要获得@my_struct第二个字段的值,我们需要
%2 = extractvalue %MyStruct %1, 1
这里的1就代表第二个字段(从0开始)。
类似地,如果要将%1的第二个字段赋值为233,只需要
%3 = insertvalue %MyStruct %1, i32 233, 1
然后%3就会是%1将第二个字段赋值为233后的值。
extractvalue和insertvalue并不只适用于结构体,也同样适用于存储在虚拟寄存器中的数组,这里不再赘述。
标签类型
在汇编语言中,一切的控制语句、函数调用都是由标签来控制的,在LLVM IR中,控制语句也是需要标签来完成。其具体的内容我会在之后专门有一篇控制语句的文章来解释。
元数据类型
在我们使用Clang将C语言程序输出成LLVM IR时,会发现代码的最后几行有
!llvm.module.flags = !{!0, !1, !2, !3}
!llvm.ident = !{!4}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 8, !"PIC Level", i32 2}
!2 = !{i32 7, !"PIE Level", i32 2}
!3 = !{i32 7, !"uwtable", i32 2}
!4 = !{!"Homebrew clang version 16.0.6"}
类似于这样的东西。
在LLVM IR中,以!开头的标识符为元数据。元数据是为了将额外的信息附加在程序中传递给LLVM后端,使后端能够好地优化或生成代码。用于Debug的信息就是通过元数据形式传递的。我们可以使用-g选项:
clang -S -emit-llvm -g test.c
来在LLVM IR中附加额外的Debug信息。关于元数据,在后续的章节里会有更具体的介绍。
属性
最后,还有一种叫做属性的概念。属性并不是类型,其一般用于函数。比如说,告诉编译器这个函数不会抛出错误,不需要某些优化等等。我们可以看到
define void @foo() nounwind {
; ...
}
这里nounwind就是一个属性。
有时候,一个函数的属性会特别特别多,并且有多个函数都有相同的属性。那么,就会有大量重复的篇幅用来给每一个函数说明属性。因此,LLVM IR引入了属性组的概念,我们在将一个简单的C程序编译成LLVM IR时,会发现代码中有
attributes #0 = { noinline nounwind optnone ssp uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "darwin-stkchk-strong-link" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "probe-stack"="___chkstk_darwin" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
这种一大长串的,就是属性组。属性组总是以#开头。当我们函数需要它的时候,只需要
define void @foo #0 {
; ...
}
直接使用#0即可。关于属性,后续也会有专门的章节进行介绍。
控制流
我在之前汇编语言的教程中,是将跳转与函数放在同一篇文章里的,因为在汇编语言中这两个概念几乎没有太大的区别。然而,到了LLVM IR中,这两者就有了比较大的区别。因此,我将其分成了多篇文章单独介绍。
在程序分析领域,往往会强调一对概念:数据流与控制流。所谓数据流,就是指一个程序中的数据,从硬盘到内存,从内存到寄存器,等等一系列的数据搬运、处理的过程。这一过程,在之前的文章中已经详细地介绍了。
而控制流,则是指程序执行指令的顺序。最简单地,我们的程序在除了顺序执行指令,还可以通过if语句进行条件跳转,通过for、while语句进行循环,还可以通过函数调用进入到别的函数。凡此种种,都是程序控制流的变化。
在使用LLVM作为编译器的时候,控制流往往就意味着更多的优化可能,如分支布局、函数内联。在使用LLVM作为静态分析工具的过程中,控制流也意味着更高的复杂度,如间接跳转、间接调用的识别和恢复。
因此,我们需要仔细了解LLVM中的控制流。
控制语句
在控制流中,最基础的就是控制语句,也就是与汇编中的跳转相关的。
汇编层面的控制语句
在大多数语言中,常见的控制语句主要有四种:
if..elseforwhileswitch
在汇编语言层面,控制语句则被分解为两种核心的指令:条件跳转与无条件跳转(switch其实还有一些工作,之后会提到)。我们下面分别来看看在汇编层面是怎样实现控制语句的。
if .. else
我们有以下C代码:
if (a > b) {
// Do something A
} else {
// Do something B
}
// Do something C
为了将这个指令改写成汇编指令,我们同时需要条件跳转与无条件跳转。我们用伪代码表示其汇编指令为:
Compare a and b
Jump to label B if comparison is a is not greater than b // conditional jump
label A:
Do something A
Jump to label C // unconditional jump
label B:
Do something B
label C:
Do something C
汇编语言通过条件跳转、无条件跳转和三个标签(label A标签实际上没有作用,只不过让代码更加清晰)实现了高级语言层面的if .. else语句。
for
我们有以下C代码:
for (int i = 0; i < 4; i++) {
// Do something A
}
// Do something B
为了将这个指令改写为汇编指令,我们同样地需要条件跳转与无条件跳转:
int i = 0
label start:
Compare i and 4
Jump to label B if comparison is i is not less than 4 // conditional jump
label A:
Do something A
i++
Jump to label start // unconditional jump
label B:
Do something B
而while与for则极其类似,只不过少了初始化与自增的操作,这里不再赘述。
根据我们在汇编语言中积累的经验,我们得出,要实现大多数高级语言的控制语句,我们需要四个东西:
- 标签
- 无条件跳转
- 比较大小的指令
- 条件跳转
LLVM IR层面的控制语句
下面就以我们上面的for循环的C语言版本为例,解释如何写其对应的LLVM IR语句。
首先,我们对应的LLVM IR的基本框架为
%i = alloca i32 ; int i = ...
store i32 0, ptr %i ; ... = 0
%i_value = load i32, ptr %i
; Do something A
%1 = add i32 %i_value, 1 ; ... = i + 1
store i32 %1, ptr %i ; i = ...
; Do something B
这个程序缺少了一些必要的步骤,而我们之后会将其慢慢补上。
标签
在LLVM IR中,标签与汇编语言的标签一致,也是以:结尾作标记。我们依照之前写的汇编语言的伪代码,给这个程序加上标签:
%i = alloca i32 ; int i = ...
store i32 0, ptr %i ; ... = 0
start:
%i_value = load i32, ptr %i
A:
; Do something A
%1 = add i32 %i_value, 1 ; ... = i + 1
store i32 %1, ptr %i ; i = ...
B:
; Do something B
比较指令
LLVM IR提供的比较指令为icmp。其接受三个参数:比较方案以及两个比较参数。这样讲比较抽象,我们就来看一下一个最简单的比较指令的例子:
%comparison_result = icmp uge i32 %a, %b
这个例子转化为C++语言就是
bool comparison_result = ((unsigned int)a >= (unsigned int)b);
这里,uge是比较方案,%a和%b就是用来比较的两个数,而icmp则返回一个i1类型的值,也就是C++中的bool值,用来表示结果是否为真。
icmp支持的比较方案很广泛:
- 首先,最简单的是
eq与ne,分别代表相等或不相等。 - 然后,是无符号的比较
ugt,uge,ult,ule,分别代表大于、大于等于、小于、小于等于。我们之前在数的表示中提到,LLVM IR中一个整型变量本身的符号是没有意义的,而是需要看在其参与的指令中被看作是什么符号。这里每个方案的u就代表以无符号的形式进行比较。 - 最后,是有符号的比较
sgt,sge,slt,sle,分别是其无符号版本的有符号对应。
我们来看加上比较指令之后,我们的例子就变成了:
%i = alloca i32 ; int i = ...
store i32 0, ptr %i ; ... = 0
start:
%i_value = load i32, ptr %i
%comparison_result = icmp slt i32 %i_value, 4 ; Test if i < 4
A:
; Do something A
%1 = add i32 %i_value, 1 ; ... = i + 1
store i32 %1, ptr %i ; i = ...
B:
; Do something B
条件跳转
在比较完之后,我们需要条件跳转。我们来看一下我们此刻的目的:若%comparison_result是true,那么跳转到A,否则跳转到B。
LLVM IR为我们提供的条件跳转指令是br,其接受三个参数,第一个参数是i1类型的值,用于作判断;第二和第三个参数分别是值为true和false时需要跳转到的标签。比方说,在我们的例子中,就应该是
br i1 %comparison_result, label %A, label %B
我们把它加入我们的例子:
%i = alloca i32 ; int i = ...
store i32 0, ptr %i ; ... = 0
start:
%i_value = load i32, ptr %i
%comparison_result = icmp slt i32 %i_value, 4 ; Test if i < 4
br i1 %comparison_result, label %A, label %B
A:
; Do something A
%1 = add i32 %i_value, 1 ; ... = i + 1
store i32 %1, ptr %i ; i = ...
B:
; Do something B
无条件跳转
无条件跳转更好理解,直接跳转到某一标签处。在LLVM IR中,我们同样可以使用br进行无条件跳转。如,如果要直接跳转到start标签处,则可以
br label %start
我们也把这加入我们的例子:
%i = alloca i32 ; int i = ...
store i32 0, ptr %i ; ... = 0
start:
%i_value = load i32, ptr %i
%comparison_result = icmp slt i32 %i_value, 4 ; Test if i < 4
br i1 %comparison_result, label %A, label %B
A:
; Do something A
%1 = add i32 %i_value, 1 ; ... = i + 1
store i32 %1, ptr %i ; i = ...
br label %start
B:
; Do something B
这样看上去就结束了,然而如果大家把这个代码交给llc的话,并不能编译通过,这是为什么呢?
Basic block
首先,我们来摘录一下LLVM IR的参考指南中Functions节的一段话:
A function definition contains a list of basic blocks, forming the CFG (Control Flow Graph) for the function. Each basic block may optionally start with a label (giving the basic block a symbol table entry), contains a list of instructions, and ends with a terminator instruction (such as a branch or function return). If an explicit label name is not provided, a block is assigned an implicit numbered label, using the next value from the same counter as used for unnamed temporaries (see above).
这段话的大意有几个:
- 一个函数由许多基本块(Basic block)组成
- 每个基本块包含:
- 开头的标签(可省略)
- 一系列指令
- 结尾是终结指令
- 一个基本块没有标签时,会自动赋给它一个标签
所谓终结指令,就是指改变执行顺序的指令,如跳转、返回等。
我们来看看我们之前写好的程序是不是符合这个规定。start开头的基本块,在一系列指令后,以
br i1 %comparison_result, label %A, label %B
结尾,是一个终结指令。A开头的基本块,在一系列指令后,以
br label %start
结尾,也是一个终结指令。B开头的基本块,在最后总归是需要函数返回的(这里为了篇幅省略了),所以也一定会带有一个终结指令。
看上去都很符合呀,那为什么编译不通过呢?我们来仔细想一下,我们考虑了所有基本块了吗?要注意到,一个基本块是可以没有名字的,所以,实际上还有一个基本块没有考虑到,就是函数开头的:
%i = alloca i32 ; int i = ...
store i32 0, ptr %i ; ... = 0
这个基本块。它并没有以终结指令结尾!
所以,我们把一个终结指令补充在这个基本块的结尾:
%i = alloca i32 ; int i = ...
store i32 0, ptr %i ; ... = 0
br label %start
start:
%i_value = load i32, ptr %i
%comparison_result = icmp slt i32 %i_value, 4 ; Test if i < 4
br i1 %comparison_result, label %A, label %B
A:
; Do something A
%1 = add i32 %i_value, 1 ; ... = i + 1
store i32 %1, ptr %i ; i = ...
br label %start
B:
; Do something B
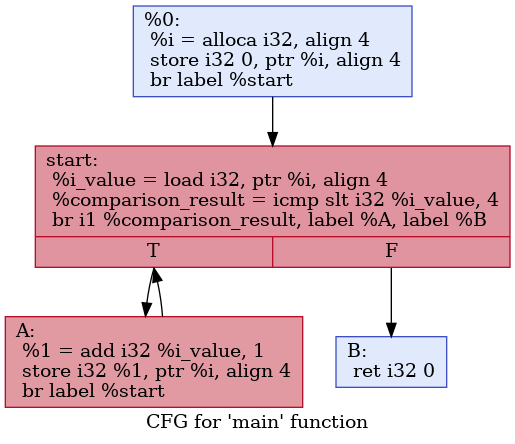
这样就完成了我们的例子,大家可以在本系列的GitHub的仓库中查看对应的代码for.ll。
可视化
LLVM的工具链甚至为我们提供了可视化控制语句的方法。我们使用之前提到的LLVM工具链中用于优化的opt工具:
opt -p dot-cfg for.ll
然后会生成一个.main.dot的文件。如果我们在计算机上装有Graphviz,那么就可以用
dot .main.dot -Tpng -o for.png
生成其可视化的控制流图(CFG):
switch
下面我们来讲讲switch语句。我们有以下C语言程序:
int x;
switch (x) {
case 0:
// do something A
break;
case 1:
// do something B
break;
default:
// do something C
break;
}
// do something else
我们先直接来看其转换成LLVM IR是什么样子的:
switch i32 %x, label %C [
i32 0, label %A
i32 1, label %B
]
A:
; Do something A
br label %end
B:
; Do something B
br label %end
C:
; Do something C
br label %end
end:
; Do something else
其核心就是第一行的switch指令。其第一个参数i32 %x是用来判断的,也就是我们C语言中的x。第二个参数label %C是C语言中的default分支,这是必须要有的参数。也就是说,我们的switch必须要有default来处理。接下来是一个数组,其意义已经很显然了,如果%x值是0,就去label %A,如果值是1,就去label %B。
LLVM后端对switch语句具体到汇编层面的实现则通常有两种方案:用一系列条件语句或跳转表。
一系列条件语句的实现方式最简单,用伪代码来表示的话就是
if (x == 0) {
Jump to label %A
} else if (x == 1) {
Jump to label %B
} else {
Jump to label %C
}
这是十分符合常理的。然而,我们需要注意到,如果这个switch语句一共有n个分支,那么其查找效率实际上是O(n)。那么,这种实现方案下的switch语句仅仅是if .. else的语法糖,除了增加可维护性,并不会优化什么性能。
跳转表则是一个可以优化性能的switch语句实现方案,其伪代码为:
labels = [label %A, label %B]
if (x < 0 || x > 1) {
Jump to label %C
} else {
Jump to labels[x]
}
这只是一个极其粗糙的近似的实现,我们需要的是理解其基本思想。跳转表的思想就是利用内存中数组的索引是O(1)复杂度的,所以我们可以根据目前的x值去查找应该跳转到哪一个地址,这就是跳转表的基本思想。
根据目标平台和switch语句的分支数,LLVM后端会自动选择不同的实现方式去实现switch语句。
select
我们经常会遇到一种情况,某一变量的值需要根据条件进行赋值,比如说以下C语言的函数:
void foo(int x) {
int y;
if (x > 0) {
y = 1;
} else {
y = 2;
}
// Do something with y
}
如果x大于0,则y为1,否则y为2。这一情况很常见,然而在C语言中,如果要实现这种功能,y需要被实现为可变变量,但实际上无论x如何取值,y只会被赋值一次,并不应该是可变的。
我们知道,LLVM IR中,由于SSA的限制,局部可变变量都必须分配在栈上,虽然LLVM后端最终会进行一定的优化,但写起代码来还需要冗长的alloca, load, store等语句。如果我们按照C语言的思路来写LLVM IR,那么就会是:
define void @foo(i32 %x) {
%y = alloca i32
%1 = icmp sgt i32 %x, 0
br i1 %1, label %btrue, label %bfalse
btrue:
store i32 1, ptr %y
br label %end
bfalse:
store i32 2, ptr %y
br label %end
end:
; do something with %y
ret void
}
我们来看看其编译出的汇编语言是怎样的:
foo:
# %bb.0:
cmpl $0, %edi
jle .LBB0_2
# %bb.1: # %btrue
movl $1, -4(%rsp)
jmp .LBB0_3
.LBB0_2: # %bfalse
movl $2, -4(%rsp)
.LBB0_3: # %end
retq
算上注释,C语言代码9行,汇编语言代码11行,LLVM IR代码14行。这LLVM IR同时比低层次和高层次的代码都长,而且这种模式在真实的代码中出现的次数会非常多,这显然是不可以接受的。究其原因,就是这里把y看成了可变变量。那么,有没有什么办法让y不可变但仍然能实现这个功能呢?
首先,我们来看看同样区分可变变量与不可变变量的Rust是怎么做的:
fn foo(x: i32) {
let y = if x > 0 { 1 } else { 2 };
// Do something with y
}让代码简短的方式很简单,把y看作不可变变量,但同时需要语言支持把if语句视作表达式,当x大于0时,这个表达式返回1,否则返回2。这样,就很简单地实现了我们的需求。
LLVM IR中同样也有这样的指令,那就是select,我们来把上面的例子用select改写:
define void @foo(i32 %x) {
%result = icmp sgt i32 %x, 0
%y = select i1 %result, i32 1, i32 2
; Do something with %y
}
select指令接受三个参数。第一个参数是用来判断的布尔值,也就是i1类型的icmp判断的结果,如果其为true,则返回第二个参数,否则返回第三个参数。极其合理。
select不仅可以简化LLVM代码,也可以优化生成的二进制程序。在大部分情况下,在AMD64架构中,LLVM会将select指令编译为CMOVcc指令,也就是条件赋值,从而优化了生成的二进制代码。
phi
select只能支持两个选择,true选择一个分支,false选择另一个分支,我们是不是可以有支持多种选择的类似switch的版本呢?同时,我们也可以换个角度思考,select是根据i1的值来进行判断,我们其实可以根据控制流进行判断。这就是在SSA技术中大名鼎鼎的phi指令。
为了方便起见,我们首先先来看用phi指令实现的我们上面这个代码:
define void @foo(i32 %x) {
%result = icmp sgt i32 %x, 0
br i1 %result, label %btrue, label %bfalse
btrue:
br label %end
bfalse:
br label %end
end:
%y = phi i32 [1, %btrue], [2, %bfalse]
; Do something with %y
ret void
}
我们看到,phi的第一个参数是一个类型,这个类型表示其返回类型为i32。接下来则是两个数组,其表示,如果当前的basic block执行的时候,前一个basic block是%btrue,那么返回1,如果前一个basic block是%bfalse,那么返回2。
也就是说,select是根据其第一个参数i1类型的变量的值来决定返回哪个值,而phi则是根据其之前是哪个basic block来决定其返回值。此外,phi之后可以跟无数的分支,如phi i32 [1, %a], [2, %b], [3, %c]等,从而可以支持多分支的赋值。
函数
这篇文章我们来讲函数。有过汇编基础的同学都知道,在汇编层面,一个函数与一个控制语句极其相似,都是由标签组成,只不过在跳转时增加了一些附加的操作。而在LLVM IR层面,函数则得到了更高一层的抽象。
定义与声明
函数定义
在LLVM中,一个最基本的函数定义的样子我们之前已经遇到过多次,就是@main函数的样子:
define i32 @main() {
ret i32 0
}
在函数名之后可以加上参数列表,如:
define i32 @foo(i32 %a, i64 %b) {
ret i32 0
}
一个函数定义最基本的框架,就是返回值(i32)+函数名(@foo)+参数列表((i32 %a, i64 %b))+函数体({ ret i32 0 })。
我们可以看到,函数的名称和全局变量一样,都是以@开头的。并且,如果我们查看符号表的话,也会发现其和全局变量一样进入了符号表。因此,函数也有和全局变量完全一致的Linkage Types和Visibility Style,来控制函数名在符号表中的出现情况,因此,可以出现如
define private i32 @foo() {
; ...
}
这样的修饰符。
属性
此外,我们还可以在参数列表之后加上属性,也就是控制优化器和代码生成器的指令。如果我们单纯编译一个简单的C代码:
void foo() {}
其编译出的LLVM IR实际上是
define dso_local void @foo() #0 {
ret void
}
attributes #0 = { noinline nounwind optnone uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
这里的#0就是一个属性组,其包含了noinline、nounwind等若干个函数的属性。这些属性可以控制LLVM在优化和生成函数时的行为。大部分的属性可以在Function Attributes一节看到。
当函数的属性比较少时,我们可以直接把属性写在函数定义后面,而不用以属性组的形式来写。例如下面这两种写法都是对的:
define void @foo() nounwind { ret void }
; or
define void @foo() #0 { ret void }
attributes #0 {
nounwind ; ...
}
我们知道,无论是在代码编译还是在程序分析的过程中,我们最常处理的都在函数级别。因此,属性在这一过程中就是一个非常关键的概念。我们在编译器前端分析的过程中,遇到了特定的函数,给它加上相应的属性;在编译器后端生成代码时,则判断当前函数是否有相应的属性,从而可以在编译器前后端之间传递信息。
函数声明
除了函数定义之外,还有一种情况十分常见,那就是函数声明。我们在一个编译单元(模块)下,可以使用别的模块的函数,这时候就需要在本模块先声明这个函数,才能保证编译时不出错,从而在链接时正确将声明的函数与别的模块下其定义进行链接。
函数声明也相对比较简单,就是使用declare关键词替换define:
declare i32 @printf(i8*, ...) #1
这个就是在C代码中调用stdio.h库的printf函数时,在LLVM IR代码中可以看到的函数声明,其中#1就是又一大串属性组成的属性组。
函数的调用
在LLVM IR中,函数的调用与高级语言几乎没有什么区别:
define i32 @foo(i32 %a) {
; ...
}
define void @bar() {
%1 = call i32 @foo(i32 1)
}
使用call指令可以像高级语言那样直接调用函数。我们来仔细分析一下这里做了哪几件事:
- 传递参数
- 执行函数
- 获得返回值
居然能干这么多事,这是汇编语言所羡慕不已的。
执行函数
我们知道,如果一个函数没有任何参数,返回值也是void类型,也就是说在C语言下这个函数是
void foo(void) {
// ...
}
那么调用这个函数就没有了传递参数和获得返回值这两件事,只剩下执行函数,而这是一个最简单的事,以AMD64架构为例:
- 把函数返回地址压栈
- 跳转到相应函数的地址
函数返回也是一个最简单的事:
- 弹栈获得函数返回地址
- 跳转到相应的返回地址
这个在我们的汇编语言基础中已经反复遇到过多次,相信大家都会十分熟练。
传递参数与获得返回值
谈到这两点,就不得不说调用约定了。我们知道,在汇编语言中,是没有参数传递和返回值的概念的,有的仅仅是让当前的控制流跳转到指定函数执行。所以,一切的参数传递和返回值都需要我们人为约定。也就是说,我们需要约定两件事:
- 被调用的函数希望知道参数是放在哪里的
- 调用者希望知道调用函数的返回值是放在哪里的
这就是调用约定。不同的调用约定会产生不同的特效,也就产生了许多高级语言的feature。
C调用约定
最广泛使用的调用约定是C调用约定,也就是各个操作系统的标准库使用的调用约定。在AMD64架构下,C调用约定是System V版本的,所有参数按顺序放入指定寄存器,如果寄存器不够,剩余的则从右往左顺序压栈。而返回值则是按先后顺序放入寄存器或者放入调用者分配的空间中,如果只有一个返回值,那么就会放在rax里。
在LLVM IR中,函数的调用默认使用C调用约定。为了验证,我们可以写一个简单的程序:
; calling_convention_test.ll
%ReturnType = type { i32, i32 }
define %ReturnType @foo(i32 %a1, i32 %a2, i32 %a3, i32 %a4, i32 %a5, i32 %a6, i32 %a7, i32 %a8) {
ret %ReturnType { i32 1, i32 2 }
}
define i32 @main() {
%1 = call %ReturnType @foo(i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 8)
ret i32 0
}
我们查看其编译出来的汇编代码。在main函数中,参数传递是:
movl $1, %edi
movl $2, %esi
movl $3, %edx
movl $4, %ecx
movl $5, %r8d
movl $6, %r9d
movl $7, (%rsp)
movl $8, 8(%rsp)
callq foo@PLT
而在foo函数内部,返回值传递是:
movl $1, %eax
movl $2, %edx
retq
如果大家去查阅System V的指南的话,会发现完全符合。
这种System V的调用约定有什么好处呢?其最大的特点在于,当寄存器数量不够时,剩余的参数是按从右向左的顺序压栈。这就让基于这种调用约定的高级语言可以更轻松地实现可变参数的feature。所谓可变参数,最典型的例子就是C语言中的printf:
printf("%d %d %d %d", a, b, c, d);
printf可以接受任意数量的参数,其参数的数量是由第一个参数"%d %d %d %d"决定的。有多少个需要格式化的变量,接下来就还有多少个参数。
那么,System V的调用约定又是为什么能满足这样的需求呢?假设我们不考虑之前传入寄存器内的参数,只考虑压入栈内的参数。那么,如果是从右往左的顺序压栈,栈顶就是"%d %d %d %d"的地址,接着依次是a, b, c, d。那么,我们的程序就可以先读栈顶,获得字符串,然后确定有多少个参数,接着就继续在栈上读多少个参数。相反,如果是从左往右顺序压栈,那么程序第一个读到的是d,程序也不知道该读多少个参数。
fastcc
各种语言的调用约定还有许多,可以参考语言指南的Calling Conventions一节。把所有的调用约定都讲一遍显然是不可能且枯燥的。所以,我在这里除了C调用约定之外,只再讲一个调用约定fastcc,以体现不同的调用约定能实现不同的高级语言的feature。
fastcc方案是将变量全都传入寄存器中的方案。这种方案使尾调用优化能更方便地实现。
尾调用会出现在很多场景下,用一个比较平凡的例子:
int foo(int a) {
if (a == 1) {
return 1;
} else {
return foo(a - 1);
}
}
我们注意到,这个函数在返回时有可能会调用自身,这就叫尾调用。为什么尾调用需要优化呢?我们知道,在正常情况下,调用一个函数会产生函数的栈帧,也就是把函数的参数传入栈,把函数的返回地址传入栈。那么如果a很大,那么调用的函数会越来越多,并且直到最后一个被调用的函数返回之前,所有调用的函数的栈都不会回收,也就是说,我们此时栈上充斥着一层一层被调用函数返回的地址。
然而,由于这个函数是在调用者的返回语句里调用,我们实际上可以复用调用者的栈,这就是尾调用优化的基础思想。我们希望,把这样的尾调用变成循环,从而减少栈的使用。通过将参数都传入寄存器,我们可以避免再将参数传入栈,这就是fastcc为尾调用优化提供的帮助。然后,就可以直接将函数调用变成汇编中的jmp。
我们来看如果用fastcc调用约定,LLVM IR该怎么写:
; tail_call_test.ll
define fastcc i32 @foo(i32 %a) {
%res = icmp eq i32 %a, 1
br i1 %res, label %btrue, label %bfalse
btrue:
ret i32 1
bfalse:
%sub = sub i32 %a, 1
%tail_call = tail call fastcc i32 @foo(i32 %sub)
ret i32 %tail_call
}
我们使用llc对其编译,并加上-tailcallopt的指令(实际上不加也没关系,LLVM后端会自动进行Sibling call optimization):
llc tail_call_test.ll -tailcallopt
其编译而成的汇编代码中,其主体为:
foo:
cmpl $1, %edi
jne .LBB0_2
movl $1, %eax
retq $8
.LBB0_2:
pushq %rax
decl %edi
popq %rax
jmp foo@PLT
我们可以发现,在结尾,使用的是jmp而不是call,所以从高级语言的角度,就可以看作其将尾部的调用变成了循环。并且,有两个操作:pushq %rax和popq %rax。这两个操作只是为了栈对齐,具体可以参考stack overflow上的回答Why does this function push RAX to the stack as the first operation?。
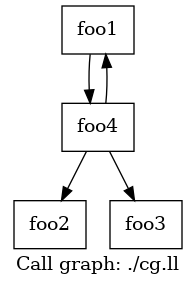
可视化
与控制语句的可视化类似,我们也可以通过LLVM工具链,获得LLVM IR的函数调用图(Call Graph)。
假设我们有以下LLVM IR:
; cg.ll
define void @foo1() {
call void @foo4(i32 0)
ret void
}
declare void @foo2()
declare void @foo3()
define void @foo4(i32 %0) {
%comparison_result = icmp sgt i32 %0, 0
br i1 %comparison_result, label %true_branch, label %false_branch
true_branch:
call void @foo1()
br label %final
false_branch:
call void @foo2()
br label %final
final:
call void @foo3()
ret void
}
foo4根据输入,调用foo1或者foo2,最终调用foo3。而foo1则递归调用foo4。
对于这样的LLVM IR,我们使用
opt -p dot-callgraph cg.ll
可以生成一个cg.ll.callgraph.dot的文件。类似CFG,我们可以使用
dot cg.ll.callgraph.dot -Tpng -o cg.png
生成如下图所示的函数调用图:
内置函数、属性和元数据
在LLVM IR中,除了基础的数据表示、控制流之外,还有内置函数、属性和元数据等,能够影响二进制程序生成的功能。
内置函数
我们回顾一下,LLVM IR的作用实际上是将编译器前端与后端解耦合。编程语言的前端开发者,负责将输入的编程语言代码进行解析,生成LLVM IR;指令集架构的后端开发者,负责将输入的LLVM IR生成为目标架构的二进制指令。因此,LLVM IR提供了若干非常基础的指令,如add、br、call等。这样做的好处在于:
- 对前端开发者而言,这些指令语义足够全,使用方法也和常见高级语言类似。
- 对后端开发者而言,这些指令相对数目比较少,提供的功能也相对较为独立,在大部分常见的指令集中都有类似的指令与其对应。
但是,这样的策略也有其弊端:
- 对前端开发者而言,仍然有部分通用的语义无法被单个指令所涵盖
- 对后端开发者而言,对一些通用指令的优化无法针对LLVM IR指令来做
memcpy
以内存拷贝为例。熟悉AMD64或者AArch64的开发者一定知道,在这些支持向量操作的指令集架构中,大规模的内存拷贝往往是通过向量指令来实现的,Glibc中的memcpy就是这样实现的。
但是对于通用编程语言来说,标准库往往不喜欢直接调用libc中的函数,会产生一些不必要的依赖。并且,memcpy用向量操作来实现已经是一个非常通用的方案了,所以能不能复用一些逻辑呢?
对于此类,LLVM IR指令过于基础,但是却非常广泛地使用同一套实现逻辑的情况,LLVM IR提供了「内置函数」(Intrinsic Functions)功能来解决。
所谓内置函数,我们可以理解成一些可以像普通的LLVM IR函数一样调用的函数,但这些函数不需要开发者自己实现,LLVM的后端开发者提供了这些函数的实现。
例如,LLVM IR提供了llvm.memcpy内置函数,以提供内存的拷贝操作。前端开发者只需要调用这个函数,就可以实现内存拷贝功能了。
我们熟知的Rust语言,在利用LLVM生成二进制程序时,就是使用的这个函数,可以参考其封装的LLVMRustBuildMemCpy与调用者memcpy。
静态分支预测
LLVM IR提供的内置函数有许多,这里,我们再以静态分支预测为例,介绍一个常见内置函数。
我们在阅读一些大规模项目源码时,例如Linux内核源码、QEMU源码等,往往会注意到大量使用的likely与unlikely,如:
if (likely(x > 0)) {
// Do something
}
这个likely是什么?它是干什么用的?事实上,likely与unlikely往往是通过宏定义实现的,它们的作用是静态分支预测。
我们知道,对于C语言等常见的编程语言的if语句,在生成二进制程序的时候,我们可以交换它的两个分支的位置。紧接着cmp等判断语句的分支,在执行时,不会发生跳转,而另一个分支则需要设置PC寄存器来跳转。这种跳转往往会造成一定程度的性能损耗,这些具体的我在「在 Apple Silicon Mac 上入门汇编语言」中的编译期分支预测一节中有详细阐述。总之,我们需要给编译器一些信息,来排布不同的分支布局。
对于Clang来说,这是通过内置expect指令来实现的,也就是说:
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
而__builtin_expect这个内置指令,就会翻译为LLVM IR中的llvm.expect内置函数,从而实现了静态分支预测。
属性
在C语言中,我们会遇到一个函数的修饰符:inline。这个修饰符会提示编译器,建议编译器在遇到这个函数的调用时,内联这个函数。这类的信息,LLVM会将其看作函数的「属性」(Attribtues)。
在之前,我们也提到过,我们可以:
define void @foo() attr1 attr2 attr3 {
; ...
}
如果有多个函数有相同的属性,我们可以用一个属性组的形式来复用:
define void @foo1() #0 {
; ...
}
define void @foo2() #0 {
; ...
}
attributes #0 = { attr1 attr2 attr3 }
LLVM支持的函数属性有多种,我们来看看几个比较容易理解的,由函数属性控制的优化:
内联
函数内联是一个非常复杂的概念,这里我们只是简单地来看一下,下面这个C语言代码:
inline int foo(int a) __attribute__((always_inline));
int foo(int a) {
if (a > 0) {
return a;
} else {
return 0;
}
}
这里声明了foo函数,并且用了一个扩展语法__attribute__((always_inline)),这个语法实际上的作用就是给函数加上alwaysinline的属性。
我们查看其生成的LLVM IR:
define dso_local i32 @foo(i32 noundef %0) #0 {
; ...
}
attributes #0 = { alwaysinline nounwind uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
可以看到,其确实有了alwaysinline这个属性。
帧指针清除优化
我们再来看一个属性控制的优化:帧指针清除优化(Frame Pointer Elimination)。
在讲这个之前,先讲一个比较小的优化。我们将一个非常简单的C程序
void foo(int a, int b) {}
int main() {
foo(1, 2);
return 0;
}
编译为汇编程序,可以发现,foo函数的汇编代码为:
foo:
pushq %rbp
movq %rsp, %rbp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
popq %rbp
与我们常识有些违背。为啥这里栈不先增加(也就是对rsp寄存器进行sub),就直接把edi, esi的值移入栈内了呢?-4(%rbp)和-8(%rbp)的内存空间此刻似乎并不属于栈。
这是因为,在System V关于amd64架构的标准中,规定了rsp以下128个字节为red zone。这个区域,信号和异常处理函数均不会使用。因此,一个函数可以放心使用rsp以下128个字节的内容。
同时,我们对栈指针进行操作,一个很重要的原因就是为了进一步函数调用的时候,使用call指令会自动将被调用函数的返回地址压栈,那么就需要在调用call指令之前,保证栈顶指针确实指向栈顶,否则压栈就会覆盖一些数据。
但此时,我们的foo函数并没有调用别的函数,也就不会产生压栈行为。因此,如果在栈帧不超过128个字节的情况下,编译器自动为我们省去了这样的操作。为了验证这一点,我们做一个小的修改:
void bar() {}
void foo(int a, int b) { bar(); }
int main() {
foo(1, 2);
return 0;
}
这时,我们再看编译出的foo函数的汇编代码:
foo:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
callq bar
addq $16, %rsp
popq %rbp
retq
确实增加了对rbp的sub和add操作。而此时的bar函数,也没有对rsp的操作。
接下来,就要讲帧指针清除优化了。经过我们上述的讨论,一个函数在进入时会有一些固定动作:
- 把
rbp压栈 - 把
rsp放入rbp - 减
rsp,预留栈空间
在函数返回之前,也有其相应的操作:
- 加
rsp,回收栈空间 - 把
rbp最初的值弹栈回到rbp
我们刚刚讲的优化,使得没有调用别的函数的函数,可以省略掉进入时的第3步和返回前的第1步。那么,是否还可以继续省略呢?
那么,我们就要考虑为什么需要这些步骤。这些步骤都是围绕rbp进行的,而正是因为rbp经常进行这种操作,所以我们把rbp称为帧指针。之所以要进行这些操作,是因为我们在函数执行的过程中,栈顶指针随着不断调用别的函数,会不断移动,导致我们根据栈顶指针的位置,不太方便确定局部变量的位置。而如果我们在一开始就把rsp的值放在rbp中,那么局部变量的位置相对rbp是固定的,就更好确认了。注意到我们这里说根据rsp的值确认局部变量的位置只是不方便,但并不是不能做到。所以,我们可以增加一些编译器的负担,而把帧指针清除。
帧指针清除在LLVM IR层面其实十分方便,就是什么都不写。我们可以观察
define void @foo(i32 %a, i32 %b) {
%1 = alloca i32
%2 = alloca i32
store i32 %a, ptr %1
store i32 %b, ptr %2
ret void
}
这个函数在编译成汇编语言之后,是:
foo:
movl %edi, -4(%rsp)
movl %esi, -8(%rsp)
retq
不仅没有了栈的增加减少(之前提过的优化),也没有了对rbp的操作(帧指针清除)。
要想恢复这一操作也十分简单,在函数参数列表后加上一个属性"frame-pointer"="all":
define void @foo(i32 %a, i32 %b) "frame-pointer"="all" {
%1 = alloca i32
%2 = alloca i32
store i32 %a, ptr %1
store i32 %b, ptr %2
ret void
}
其编译后的汇编程序就是:
foo:
pushq %rbp
movq %rsp, %rbp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
popq %rbp
retq
恢复了往日的雄风。
元数据
函数的属性可以在前后端之间传递函数的信息,例如,前端发现某个函数需要后端的特殊处理,就给这个函数加一个自定义的属性。而在LLVM的整个管线中的任意一个位置,我们往往都能读到这个属性,从而可以依据是否有这个属性来做特殊的处理/优化。正因如此,之所以函数要有属性,是因为函数是LLVM的优化过程中一个非常重要的基础单元,因此需要保留各种信息。
除此之外,我们有时也会希望每一条指令,或者每一个翻译单元,都可以有类似属性一样的信息,可以在管线中传递/过滤,从而能获得一些信息。这在LLVM IR中被称为「元数据」(Metadata)。
调试信息
说了这么多,元数据具体有什么用处呢?元数据的语法又是怎样的呢?我们来看一个具体的例子。
我们知道,在Clang中,传入-g选项可以生成调试信息。那么,调试信息是怎么在LLVM IR中体现的呢?
我们这样一个debug.c文件:
int sum(int a, int b) {
return a + b;
}
我们使用
clang debug.c -g -S -emit-llvm
生成LLVM IR文件,其一部分如下:
; ...
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @sum(i32 noundef %0, i32 noundef %1) #0 !dbg !10 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 %0, ptr %3, align 4
call void @llvm.dbg.declare(metadata ptr %3, metadata !15, metadata !DIExpression()), !dbg !16
store i32 %1, ptr %4, align 4
call void @llvm.dbg.declare(metadata ptr %4, metadata !17, metadata !DIExpression()), !dbg !18
%5 = load i32, ptr %3, align 4, !dbg !19
%6 = load i32, ptr %4, align 4, !dbg !20
%7 = add nsw i32 %5, %6, !dbg !21
ret i32 %7, !dbg !22
}
; ...
!llvm.dbg.cu = !{!0}
!llvm.module.flags = !{!2, !3, !4, !5, !6, !7, !8}
!llvm.ident = !{!9}
!0 = distinct !DICompileUnit(language: DW_LANG_C11, file: !1, producer: "Homebrew clang version 16.0.6", isOptimized: false, runtimeVersion: 0, emissionKind: FullDebug, splitDebugInlining: false, nameTableKind: None)
!1 = !DIFile(filename: "debug.c", directory: "...", checksumkind: CSK_MD5, checksum: "...")
; ...
!10 = distinct !DISubprogram(name: "sum", scope: !1, file: !1, line: 1, type: !11, scopeLine: 1, flags: DIFlagPrototyped, spFlags: DISPFlagDefinition, unit: !0, retainedNodes: !14)
!11 = !DISubroutineType(types: !12)
!12 = !{!13, !13, !13}
!13 = !DIBasicType(name: "int", size: 32, encoding: DW_ATE_signed)
!14 = !{}
!15 = !DILocalVariable(name: "a", arg: 1, scope: !10, file: !1, line: 1, type: !13)
!16 = !DILocation(line: 1, column: 13, scope: !10)
!17 = !DILocalVariable(name: "b", arg: 2, scope: !10, file: !1, line: 1, type: !13)
!18 = !DILocation(line: 1, column: 20, scope: !10)
!19 = !DILocation(line: 2, column: 12, scope: !10)
!20 = !DILocation(line: 2, column: 16, scope: !10)
!21 = !DILocation(line: 2, column: 14, scope: !10)
!22 = !DILocation(line: 2, column: 5, scope: !10)
我们可以看到,在生成的LLVM IR中,出现了大量以!开头的符号,这就是元数据的语法。
具体而言,我们看到其中的
!12 = !{!13, !13, !13}
!13 = !DIBasicType(name: "int", size: 32, encoding: DW_ATE_signed)
这里,!13 = ...生成了一个元数据,其内容为一个给定的结构体DIBasicType,而!12这个元数据的内容,则并不是一个给定的结构体,而是由三个!13这个元数据组成的结构。也就是说,元数据的组织相对比较灵活。
在sum函数体中,我们可以看到,几乎每条指令后都附加了一个元数据,在代码下半部分找到对应的元数据,其实就是这行指令对应C语言中源代码里的位置,也就是调试信息中的location。
此外,我们还可以看到llvm.dbg.declare内置函数的调用。这个函数的作用是标记源代码中变量的地址。例如:
store i32 %0, ptr %3, align 4
call void @llvm.dbg.declare(metadata ptr %3, metadata !15, metadata !DIExpression()), !dbg !16
这里就是指,源代码中位于!15元数据处的变量,也就是a,其在生成的二进制程序中,位于%3变量。
LLVM中的调试信息非常全面且复杂,具体可以看官方文档Source Level Debugging with LLVM。
控制流完整性
元数据的另一个用途,就在于控制流完整性保护。当一个攻击者攻击一个二进制程序的时候,最低级的攻击者只是让它崩溃,造成DoS攻击。高级的攻击者,往往想让这个程序执行自己想让它执行的命令。而这一途径,在现代攻击环境下,往往是通过函数指针覆盖来实现的。
举一个例子来说,在前几年,有一个非常著名的漏洞checkm8。这个漏洞可以攻击苹果的大部分iPhone设备,并且由于代码处于ROM中,所以被认为无法修复。其具体的分析可以看Technical analysis of the checkm8 exploit和iPhone史诗级漏洞checkm8攻击原理浅析 - Gh0u1L5的文章 - 知乎。我们这里只需要了解一点,它的核心是,Apple代码中有一个结构体
struct usb_device_io_request {
void *callback;
// ...
};
这里callback是一个函数指针,在程序执行中会被调用。攻击者通过某种方法,强行覆盖了这个函数指针的值,从而让程序执行自己想要执行的函数。
为了抵御这种攻击,我们往往会采用控制流完整性(Control Flow Integrity, CFI)策略。最简单的思路是,我们在写程序时,函数指针所指向的函数,肯定是有限个确定的函数。那么,我们可以在执行函数指针所对应的间接调用时,检查调用目标是否是那有限个确定的函数,就可以保证不会出现之前的这种问题了。
但是,如何确定这个函数指针究竟能指向哪些函数呢?这个问题非常复杂,编译器往往是做不到这件事的。因此,现在一般会使用比较弱化的控制流完整性策略。在LLVM中,我们可以通过传递-fsanitize=cfi-icall来启用LLVM-CFI所提供的控制流完整性策略(需要同时通过-flto开启LTO),例如,我们有以下程序:
typedef void (*f)(void);
void foo1(void) {}
void foo2(void) {}
void bar(int a) {}
void baz(f func) {
func();
}
将其保存为cfi.c,然后在命令行中使用
clang cfi.c -flto -fsanitize=cfi-icall -S -emit-llvm
可以生成一个开启了LLVM-CFI策略的LLVM IR代码。
那么,LLVM-CFI策略是什么呢?由于其相对比较复杂,具体可以参考Control Flow Integrity Design Documentation,我们这里只是非常粗略地讲。
在上述代码中,baz函数接收一个函数指针,然后调用了这个函数指针。这个函数指针的类型是,不接收参数,也没有返回值。而LLVM-CFI采用的策略则是,只要满足这个类型的函数,都被认为是可以被函数指针所指向的。反之,如果不满足,则被拒绝。也就是说,在这个代码中,foo1、foo2都是满足的,而bar函数,因为它接收一个int类型的参数,所以不满足。
那么,具体是怎么实现的呢?我们来看看它的LLVM IR代码,其一部分为:
; Function Attrs: noinline nounwind optnone uwtable
define dso_local void @foo1() #0 !type !9 !type !10 {
ret void
}
; Function Attrs: noinline nounwind optnone uwtable
define dso_local void @foo2() #0 !type !9 !type !10 {
ret void
}
; Function Attrs: noinline nounwind optnone uwtable
define dso_local void @bar(i32 noundef %0) #0 !type !11 !type !12 {
%2 = alloca i32, align 4
store i32 %0, ptr %2, align 4
ret void
}
; Function Attrs: noinline nounwind optnone uwtable
define dso_local void @baz(ptr noundef %0) #0 !type !13 !type !14 {
%2 = alloca ptr, align 8
store ptr %0, ptr %2, align 8
%3 = load ptr, ptr %2, align 8
%4 = call i1 @llvm.type.test(ptr %3, metadata !"_ZTSFvvE"), !nosanitize !15
br i1 %4, label %6, label %5, !nosanitize !15
5: ; preds = %1
call void @llvm.ubsantrap(i8 2) #3, !nosanitize !15
unreachable, !nosanitize !15
6: ; preds = %1
call void %3()
ret void
}
!9 = !{i64 0, !"_ZTSFvvE"}
!10 = !{i64 0, !"_ZTSFvvE.generalized"}
!11 = !{i64 0, !"_ZTSFviE"}
!12 = !{i64 0, !"_ZTSFviE.generalized"}
可以看到,在baz函数中,在调用这个函数指针,也就是call void %3()之前,被插入了一部分代码:
%3 = load ptr, ptr %2, align 8
%4 = call i1 @llvm.type.test(ptr %3, metadata !"_ZTSFvvE"), !nosanitize !15
br i1 %4, label %6, label %5, !nosanitize !15
5: ; preds = %1
call void @llvm.ubsantrap(i8 2) #3, !nosanitize !15
unreachable, !nosanitize !15
在这里,首先调用了llvm.type.test这个内置函数。这个内置函数的作用是查看ptr %3这个函数的类型,是否是!"_ZTSFvvE"这个元数据所代表的类型,如果不是的话,就跳转,调用llvm.ubsantrap报告错误。而我们可以看到,foo1、foo2、bar都被附加了一些元数据,查看代码的下半部分,可以看到,foo1、foo2的元数据是!"_ZTSFvvE",而bar的元数据是!"_ZTSFviE"。因此,如果攻击者想让这个间接调用前往bar函数,就会被拒绝,从而保护了控制流的完整性。